Error detection and correction
What's it all about?
See teaching this in action

The world is a complicated and imperfect place, and errors can occur whenever information is stored or transmitted. Data stored on hard disks, DVDs and flash memory can be changed if there is a tiny fault in the device (and these occur regularly!). Information received over networks can be corrupted if there's interference on the line or a faulty component in the system. Even scanning information from barcodes and QR codes is a form of information transmission, and small errors such as dirt or scratches on the code can change the information. Yet we rely on data so much that there could be serious implications from even a single digit error in a student's grade, or a small change to a payment, or an incorrect reading in a medical scan. Error detection techniques add extra information to data to determine when errors have occurred. The extra information might be an extra "check digit" such as the last digit of a credit card number or barcode number on a product, or extra binary digits (bits) in data stored on a computer.

Not only can most digital systems detect errors, but many can correct them as well, back to what the data should have been. Error correction can appear to be magic, since it involves being able to put data back to how it was originally, even when you don’t know what the original data was. In fact, the first lesson plan presents a technique called "parity error correction" as a magic trick that most audiences find intriguing. In the trick the demonstrator is “magically” able to figure which one out of dozens of cards has been turned over, using the same kind of method that computers use to figure out when and where an error has occurred in a piece of data.

A related technique is used on the barcodes printed on products to check that they are scanned correctly at a checkout; the last digit in the product code is based on a mathematical combination of all the other digits, and can easily be calculated from them. If the calculation comes up with a different value for the last digit, it's a warning that one of the digits is wrong, in which case the scanner gives a warning, and the operator might have to scan the item again, or type in the number, or look it up some other way.
The lessons in this unit show how errors can be detected, and in same cases, corrected to restore the original data. It also enables students to explore how we use some relatively simple ideas to make our digital systems so reliable that people using them don't realise that this is all happening underneath the surface!
See teaching this in action
A demonstration of lesson one ("Parity magic") being taught is available here:
Digital Technologies | Data Representation
When data is stored on a disk or transmitted from one computer to another, we usually assume that it doesn’t get changed in the process. We are going to learn about some ways in which computers make sure that information can be retrieved reliably even when errors have occurred. The digital nature of the data (i.e. it is made up of digits) is what allows us to detect and correct these errors.
Vocabulary Explained
Error detection is a method that can look at some data and detect if it has been corrupted while it was stored or transmitted.
Error correction is a step better than error detection; when it detects an error it tries to put the data back to how it should have been.
Error control is the general term for error correction and error detection systems.
“Parity” often comes up in error control as there is a well-known method based on it. The word "parity" has a general meaning of simply saying if a number is even or odd. It comes from the same root word as “pair” – even parity means that there is an even number of objects (they can be put in pairs), and odd parity means they can’t be put into pairs. If you have 5 white socks, then they have odd parity, but you want them to have even parity! The system described in lesson plan one uses even parity, as it is slightly easier to work with in this situation; so "even parity" is just a fancy way of saying that there is an even number of something.
A "check digit" is an extra digit added to the end of an important number such as a credit card number, product code (bar code), identity number, tax number, or a passport number, that can be used to check if the number has been typed in correctly. In some situations more than one digit is used, in which case it is referred to as a checksum.
Mathematical links
- Even and odd numbers.
- That even and odd numbers alternate (adding or subtracting one from a number changes it from even to odd, or from odd to even). Mathematically, if N is even, then N + 1 and N -1 are odd.
- Basic facts knowledge (adding, multiplying).
- Clock arithmetic (can also be presented as remainder from division, or the modulo operator).
Real world implications

Imagine that you send an email to an online trader saying that you will pay $20 for their product. But suppose some interference occurs along the way, and the $20 is changed to $80. The trader will probably be very happy to accept your offer, and charge you 4 times as much for the product as you wanted to pay! Or what if someone types in a credit card number to buy something, but gets one digit wrong? Someone else might get charged for the item and person who mis-typed the number might be accused of fraud just because of a simple typing mistake.
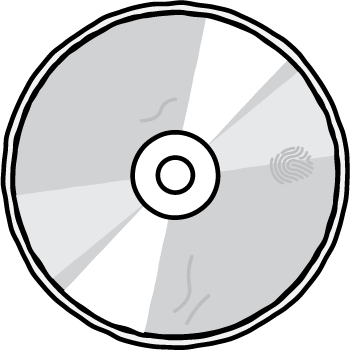
Everything stored by computers and sent between them is represented as bits (binary digits). It is easy for these to be changed accidentally because of errors in the devices that are storing or transmitting them. A CD might get a scratch or a piece of dust on it that changes a zero into a one or vice versa. A hard disk might have the magnetism accidentally fade where a bit (binary digit) is stored. On the Internet, interference and bad connections can cause bits to be altered. When scanning printed information such as barcodes and QR codes there might be ice or dirt on the product that causes the wrong value to be scanned. So how come we don’t have to worry about this?
And even worse, what if we detect that there's been an error in the data, but can't get a new copy? For example, if data is received from a deep space probe, it would be very tedious to wait for retransmission if an error has occurred and we can’t fix it! (It takes just over half an hour to get a radio signal from Jupiter when it is at its closest to Earth!) And when you read data from a computer's file system, if an error is detected you can't go back in time and save a new copy (well, making a backup is like anticipating that you'll need to go back in time one day, but it's not always convenient or easy to remember to use a backup). We need to be able to recognize when the data has been corrupted (error detection) and ideally we also need to be able to reconstruct the original data (error correction).
This was a serious problem on early computers, so scientists soon invented methods to allow computers to detect errors in data and correct those errors. We will learn about one way to do this using a method that is called parity. But instead of using zero and one bits inside a computer system, we’ll use cards with two sides, and do it as a magic trick. More sophisticated versions of this are widely used on modern storage and transmission devices to make sure that typical minor hardware problems are unlikely to result in a major loss of data. The more complex error control systems used on modern digital devices are able to detect and correct multiple errors. The hard disk in a computer has a large amount of its space allocated to correcting errors so that it will work reliably even if parts of the disk surface fail. The activities here will show how adding extra information (without going to the trouble of making a whole backup, which would use twice the space) provides a good level of resilience against errors.
Reflection questions
- What was most surprising about the learning that happened from the teaching of this unit?
- Who were the students who were very systematic in their activities?
- Who were the students who were very detailed in their activities?
- What would I change in my delivery of this unit?
Seeing the Computational Thinking connections
Throughout the lessons there are links to computational thinking. Below we've noted some general links that apply to this content.
Teaching computational thinking through CSUnplugged activities supports students to learn how to describe a problem, identify what are the important details they need to solve this problem, break it down into small logical steps so that they can then create a process which solves the problem, and then evaluate this process. These skills are transferable to any other curriculum area, but are particularly relevant to developing digital systems and solving problems using the capabilities of computers.
These Computational Thinking concepts are all connected to each other and support each other, but it’s important to note that not all aspects of Computational Thinking happen in every unit or lesson. We’ve highlighted the important connections for you to observe your students in action. For more background information on what our definition of Computational Thinking is see our notes about computational thinking.
Algorithmic thinking
How to detect and correct errors in data is a very important problem in Computer Science, and to solve this problem we need algorithms. Asking “Has this barcode been scanned correctly?” has a yes or no answer, and means you can perform error control on that specific barcode, but it is not a solution to the bigger problem of “How do we perform error control for barcodes?”. The solution to that problem is an algorithm, and if we use that algorithm we can check any barcode we are given and find out if it is correct or not.
Abstraction

When we perform error control there are only some details we need to focus on to perform this task, and many others can be ignored by using abstraction when we look at the problem. With error control, we only care about what the bits or numbers we are looking at are, and we don’t need to know what those bits and numbers actually represent or mean - we don’t need to know if they are the numbers and check digit on the barcode for a loaf of bread, or if the bits we are checking for even parity represent a video stored on a laptop. This information can be discarded because it is irrelevant to the task of error control. Similarly, if we have performed error control on our piece of data and now we are using it for something, we no longer need to think about how that error detection and correction worked; it is usually hidden from the user, so all they see is data that seems to be stored and transmitted accurately. The designer of such a system needs to know error control is enabling the data to get through accurately, but once that is happening, they can put all the information about how it is happening to one side and focus on working with the data.
Decomposition
To solve our problem of performing error control we need to break this problem down into smaller components. The instruction “Detect the error in this data and correct it” involves many steps and can’t be solved all at once! First it needs to be broken down into smaller steps and then each of these can be solved.
Generalising and patterns

Detecting and correcting errors is a very common problem in Computer Science, and it relates to data validation in general, which is important for security and encryption as well. Seeing the similarities between each of these problems allows us to generalise the algorithms we use to multiple situations where we need to find out if data has been changed or not. For example, the simple single-digit checksum used on product codes can be generalised to multiple-digit checksums used for some ID numbers, through to checksums that are dozens of digits long that are used to check the downloaded files have arrived reliably.
Evaluation

We can evaluate our solutions by testing them with a range of different inputs. Does our solution detect when data has an error in it or not? What happens if there is more than one error in our data? Students can test the algorithms with many different inputs to evaluate how good (or not good!) they are. We can also evaluate our algorithms like the ones in this unit, and show that they will always work by constructing a mathematical proof, or through logical reasoning, which ties in with the next Computational Thinking skill: logic.
Logic

If we have even parity in the magic trick, why will flipping a card always cause the number of white cards to become odd? There is a logical reason for this and getting students to articulate that this is because of the relationship between even and odd numbers is a way to exercise their logical reasoning and maths understanding. If we know that the data in our parity trick grid should have even parity, how do we determine which card has been flipped? We can follow an algorithm to do this, but we need to use our logic skills to construct this algorithm and understand why it works.