The previous lessons in the Searching algorithms unit have shown that the way we organise data can affect which algorithms we can use for searching through it.
An unsorted list can't be searched with a binary search; the only way to search through it is to use a sequential search.
A sequential search could be used to search a sorted list, but when the list is sorted we can use a binary search, which is a much faster algorithm.
In computer science, the way we organise data to make it easier to work with is called a data structure.
A sorted list is a very simple kind of data structure, where the way it is organised makes binary search possible.
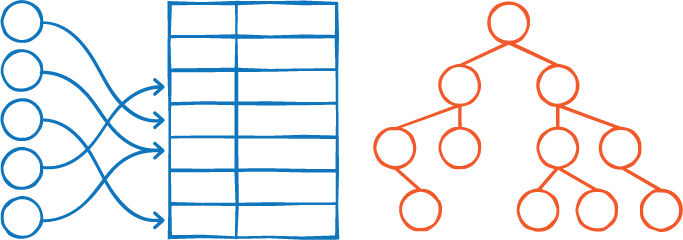
In this unit we'll look at two completely different data structures, binary search trees and hash tables, that are commonly used as the basis for searching when it is done in practice on computers.
Both have close ties to sequential and binary search, but they are more flexible in most practical situations.
It’s great to study these, because they give insights into unexpected ways that we can make programs work better.
In practice they are often built into programming languages, so you don’t need to write your own code for them, but even if you don’t need to build one yourself, it’s good to understand how they work, and what their strengths and weaknesses are.
Computer scientists generally think of a searching problem as being supplied with a "key", such as an account number, person's name, or geographic location, and looking up some values associated with that key, such as the account balance, address, or name of a building.
For example, if you search for a city using an online map, the name of the city is the key, and the data associated with it is its location on the map.
Sometimes you just need to know if the key exists; for example, a spelling checker might search for a word, and if it's not in the dictionary then it can mark it as an error.
Digital Technologies | Data Structures
One of the data structures that will be explained in this unit is the binary search tree; these have a lot of the same benefits as sorted lists, but make it a lot easier to keep the data organised.
Trees in general come up a lot in computer science because they provide a very structured way to keep information organised.
The structure of folders used on a personal computer is a type of tree - so studying a particular kind of tree called a binary search tree is a good introduction to ideas that keep coming up when developing software.
Another structure that we introduce in this unit is a hash table.
These are similar to a list of data, but data is placed at very specific points in the list, rather than being in a completely random or a completely sorted order.
The main idea of a hash table is that you can apply a simple calculation (called a hash function) to the key that you're looking for, and that will tell you where to look for it in the hash table.
This means it gives instant access (most of the time) to the information you’re looking for.
Of course, there are a lot of details that we need to get right to make this work well, but hashing is the basis of the fastest methods for searching.
The idea of hashing comes up in other areas of computer science too, and is even an essential part of how organisations can store passwords securely.
Teaching observations
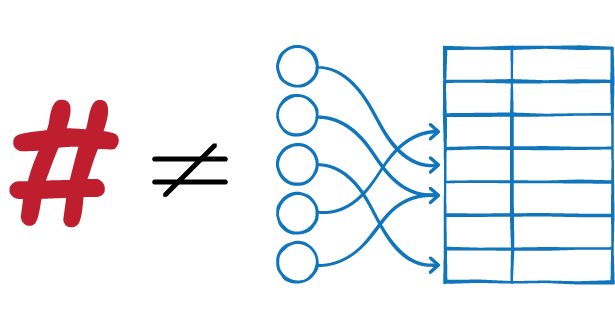
Students may try to make a connection between hashing and using hashtags.
They are actually completely different things.
The names have different derivations, and just happen to be the same word (hashtag is from the shape of the # symbol, which in turn is probably related to the word “hatch”, whereas hashing is based on mixing up the symbols that represent a value, which is more related to the usage in “hash browns”, derived from the French word “hacher”, which means to chop up).
Hashing when dealing with searching data should be treated as a completely new concept from hashtags, although confusingly, when you search for a hashtag, it may well be found using a hash table!
Vocabulary Explained
Hashing
Taking a number, word, or other item being searched for, and converting it to a number using a mathematical function.
This number can be used to find out where the data is stored.
For example, a simple way to hash a word into a number is to convert each letter to a number (e.g. a=1, b=2...), and add up those numbers.
One way function
A calculation that is easy to do one way, but hard to run backwards.
For example, you might be able to work out 2,111 x 3,709 by hand, but can you work out which two values multiply together to give 55,315,681?
Data structure
A way of organising data so that it can be accessed more efficiently.
Tree
Any structure where you can start at a “root” and follow branches to access information.
As well as search trees (which we focus on here), the same kind of structures occur in many other situations, including family trees, organisational charts and file systems.
Key
The value that we want the computer to search for.
Typically it’s a login name, customer number, product name, or anything that someone might type into a search box in an app or web site.
Real World Implications
Binary search trees are also the basis of a commonly used structure where the relationships between the keys are important - especially if you're looking for values similar to the one being searched for.
Hashing, and using hash functions supports programmers to make really fast searching algorithms.
This approach might seem almost fanciful at first because it relies a lot on randomness - making a very random value by chopping up and mixing the key you're searching for, and hoping that not too many other things come out to the same value.
Fortunately the statistics around this are well understood, and people can design very fast and efficient hash tables.
There are many variations on hash tables and search trees, but chances are that if you are looking something up on a computer system it will be using software based on these ideas, whether it's checking your online account balance, getting the price of a product in a shop, or looking for a web page using a search engine.
Reflection Questions
What was most surprising about the learning that happened from the teaching of this unit?
Who were the students who were very systematic in their activities?
Who were the students who were very detailed in their activities?
What would I change in my delivery of this unit?
Seeing the Computational Thinking connections
Throughout the lessons there are links to computational thinking. Below we've noted some general links that apply to this content.
Teaching computational thinking through CSUnplugged activities supports students to learn how to describe a problem, identify what are the important details they need to solve this problem, break it down into small logical steps so that they can then create a process which solves the problem, and then evaluate this process. These skills are transferable to any other curriculum area, but are particularly relevant to developing digital systems and solving problems using the capabilities of computers.
These Computational Thinking concepts are all connected to each other and support each other, but it’s important to note that not all aspects of Computational Thinking happen in every unit or lesson. We’ve highlighted the important connections for you to observe your students in action. For more background information on what our definition of Computational Thinking is see our notes about computational thinking.
Algorithmic thinking
Searching through data is something computers do all the time - just think about how often we need to search for words in documents and information on the internet!
Searching efficiently is a very important problem, and computer scientists have worked for a long time on solving this.
To solve this problem we need algorithms - processes that computers can follow each time we search for something, and many different algorithms have been developed.
Each of these algorithms can be seen as a solution to a problem.
In this Unit students will be exploring algorithms for using two different data structures: hash tables, and binary search trees.
For each of these data structures they will be learning and following algorithms for creating the structures, searching through them, and adding data to them.
These algorithms are different for each of these data structures, but they are also linked to the sequential search algorithm and the binary search algorithm.
Abstraction
We often have to deal with large amounts of data and complexity when we are working on computational problems.
To help us manage that complexity we can use data structures to organise and represent data in a certain way.
Using data structures is a way of encapsulating the data so that we can focus on what the data represents, rather than the details of how each individual piece of data is used.
The two data structures explored in this unit are hash tables, and binary search trees.
These data structures each store and organise data in different ways and have different structures, but both allow you to do the same thing - search for, and find data very quickly.
If you simply want to use one of these data structures (rather than creating one and implementing it on a computational device) to find data, you don’t need to think about every small step it goes through to find the data for you - in fact, this information is often hidden.
All you need to focus on is that when you search for something, it will be found quickly for you.
When programmers develop software they often use libraries, which contain many pre-programmed data structures (such as hash tables) that they can use in their own programs.
This is very helpful because it means they don’t need to spend their time re-implementing these data structures, they don’t need to worry about all the nitty-gritty details, and the code in these libraries has already been very thoroughly tested.
Decomposition
Using data structures allows us to view a problem from a higher level, without having to focus on each individual part of how the problem, and its solution, work.
But to create good data structures and understand how, and why they work, we need to break them down into their components and see how each of these functions and how they fit together.
To implement these data structures we have to focus on smaller details, and the step-by-step processes that are carried out when we create one of these structures, add data into it, search for data, and remove it.
In this unit there is also an important example of the divide and conquer method, which we looked at in the sequential and binary search unit.
Divide and conquer algorithms decompose a task into parts, and deal with the smaller parts individually.
Binary search trees can be highly efficient because they are based on using the divide and conquer method to search for data, and do this in a very similar way to binary search.
Generalising and patterns
There are many patterns (some algorithmic, some mathematical, and some abstract concepts) that appear throughout this unit.
We have included several in our explanations, but it’s possible that students will come across more as well!
Hashing, and using hash functions, is a strategy that appears in many different areas in Computer Science.
Along with searching, it is common in error detection and correction, in cryptography, and in security.
In fact, if you have learnt about check digits in the Error Detection and Correction unit, then you have already used a simple hash function - the formula we use to calculate a check digit is a hash function.
When we use hash tables for searching we use hash functions to locate data, and in these other areas it is used to validate data and check it is correct.
Some of the hash functions used in this unit, for specific sized hash tables, follow a pattern.
This pattern can be used to make an algorithm that means we can apply these hash functions to hash tables of any size.
This means we can generalise our hash function so it is applicable in a range of situations.
There are many different types of data structures - in fact, people create them all the time to fit with specific problems or types of data, but there are several well established ones which most other data structures are based on.
Often students learn the general properties of various structures to help choose between them.
Evaluation
Different data structures have different strengths and weaknesses, there is no magical data structure that will perfectly suit any problem!
So when we decide which data structure(s) to use when solving a problem we need to take into account several factors, for example: what type(s) of data are we going to be using? Is speed important for this task? Is it important that we don’t use too much computer memory? Is it ok if it is occasionally slow if that means most of the time it is really fast?
For example, binary search trees work well if items are added to them in a random order, but they can become very inefficient if you add data in an already sorted order!
Evaluating how fast these algorithms will be with different kinds of input will be crucial to understanding how fast a computer program will work in these different situations.
The factors you need to think about will be different for different problems, and in some cases there are factors which will only matter if you are actually programming your solution (such as how much memory it uses).
When we select which data structures to use we must evaluate them based on these factors, and choose the one we think is most suitable for the problem.
When we create our data structures we also have to evaluate the individual parts of them to ensure they function well.
For example, it is important to evaluate how random the hash function that a hash table uses is.
Logic
To design data structures we must use our logic skills.
For example, in a binary search tree, each decision going through the tree is based on the logic that a range of values can only be down one particular branch because of the rules around how the tree was constructed.
We can extend logical reasoning to work out where the smallest value in a tree is, and also, for a given value, where the next largest one will be.
In hash tables, we need to design the hash function we choose, as it has a large impact on how we store data in the hash table, and this in turn has a large impact on how quickly we can search through it.
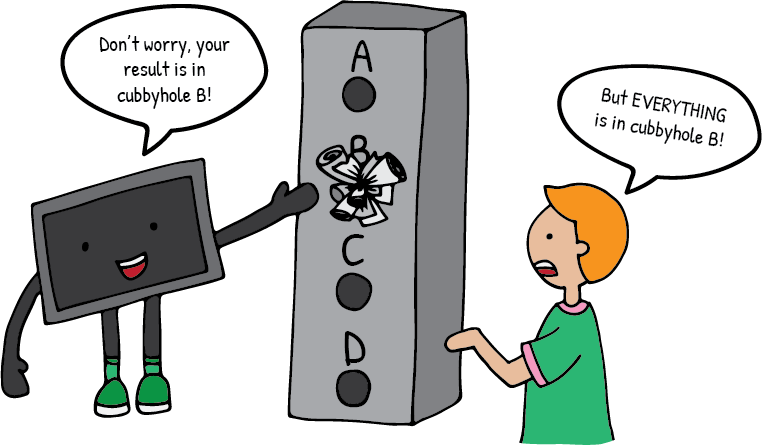
What are some things a good hash function should do?
If we want to be able to find things in the hash table quickly then it won’t be a good thing if our hash function places everything in the same slot in the table, because then we will have to search through all the data in that slot.
This would make our hash table rather pointless.
But if the data is spread out within the table then it is much more likely that we will find the correct piece of data on our first check.
Therefore a good hash function should ensure that every piece of data will end up in a different slot in the table.
In some of the examples we added the digits of a value together to get a hash value.
But what would happen if we multiply them together?
This might appear to produce a better range of values, but (applying some logic) we can realise that if any of the digits is a zero, then the hash total will be zero, so this value will become more likely to occur.
There are many other combinations of arithmetic we could apply, but good reasoning needs to be applied to make sure that it doesn't turn out to hash a large number of values to the same place.